
100+ Kubernetes Interview Questions
Kubernetes interview questions will evaluate your knowledge of architecture, deployment, networking, security, and more. This article discusses Kubernetes interview questions and how to answer them. Kubernetes is a leading open-source container orchestration framework for managing containerized workloads at scale. As more firms use Kubernetes, the need for trained workers has grown.

Q.1 What is Kubernetes, and what are some of its key features?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications.
Kubernetes is an open-source container orchestration technology that deploys, scales, and manages containerized applications. Features:
- Container orchestration: Kubernetes automates containerized application deployment and scalability, simplifying distributed system management.
- Service discovery and load balancing: Kubernetes’ built-in service discovery lets containers discover and interact. Built-in load balancing distributes traffic across numerous application instances.
- Self-healing: Kubernetes monitors container health and restarts failed or unresponsive containers. It can also auto-replace failing containers.
- Rollouts and rollbacks: Kubernetes simplifies application update rollouts and rollbacks, minimising downtime.
- Resource utilisation: Kubernetes monitors and optimises resource utilisation to ensure containers are deployed with the right resources and minimise waste.
- Multi-cloud and hybrid cloud support: Kubernetes can be installed on many cloud providers, making containerized application management straightforward.
Q.2 What are the benefits of using Kubernetes?
Kubernetes manages containerized apps with many benefits:
- Scalability: Kubernetes easily scales containerized applications up or down to handle traffic or demand fluctuations.
- Availability: Kubernetes automatically detects and replaces failed containers to keep applications running.
- Efficiency: Kubernetes optimises resource use to launch containers with the right resources and minimise waste.
- Portability: Kubernetes may be installed on many cloud providers, making containerized application management straightforward.
- Automation: Kubernetes automates numerous containerized application deployment, scaling, and management activities, freeing teams to focus on higher-level responsibilities.
- Flexibility: Kubernetes offers many container runtimes, storage solutions, and networking plugins, allowing teams to choose the best technologies.
Q.3 What is a pod in Kubernetes?
Pods are the smallest deployable unit in Kubernetes. A Kubernetes pod is a single instance of a running process that can contain one or more tightly connected containers that share the same network namespace, storage, and other resources.
The localhost interface allows pod containers to communicate. This simplifies deployment and management of multi-container apps that collaborate to complete a task.
Kubernetes API objects can create and schedule pods to operate on a cluster node. Higher-level Kubernetes controllers like deployments or stateful sets produce and manage pods with additional features for managing and scaling them.
Click Here to Read Terraform Interview Questions
Q.4 What is a Kubernetes deployment?
Kubernetes deployments update Pods and ReplicaSets declaratively. Deployments oversee pod formation, scaling, and container image upgrades and rollbacks.
When you make a deployment, you define the number of replicas, container image, and other pod configurations. The deployment controller produces and manages ReplicaSets to achieve the required state.
Rolling image updates and rollbacks are an important aspect of Kubernetes deployments. Kubernetes produces a new ReplicaSet with the revised deployment container image and progressively scales it up while scaling down the old one. This method streamlines updates with minimal downtime.
Kubernetes can revert by scaling down the new ReplicaSet and scaling up the old one if an update fails. This lets the application be restored quickly.
Kubernetes deployments make it easy to create, scale, and update pods in a cluster, ensuring that applications function as expected and can be updated and rolled back.
Q.5 What is a Kubernetes service?
A service in Kubernetes abstractly exposes an application running on Pods as a network service. A service gives other applications a stable IP address and DNS name to contact Pods, even if they are running on different nodes in a cluster or are replaced during updates.
Deployments and StatefulSets use Kubernetes API objects to create services automatically. A service’s target Pods, port, and protocol are specified when it’s created.
Kubernetes offers several services:
- ClusterIP: The default service type gives a cluster-only virtual IP address.
- NodePort: This service type exposes the service on a port on each cluster node, allowing outside access.
- LoadBalancer: This service type uses a cloud provider’s load balancer.
- ExternalName: This service type gives a DNS name for external apps to use.
Q.6 What is a Kubernetes namespace?
Kubernetes namespaces construct virtual clusters within actual clusters. Namespaces help manage and isolate applications and users by dividing cluster resources into logically defined groups.
Each namespace has Pods, Services, Deployments, and ConfigMaps. Namespaces can also give users and programmes varied access and resource quotas.
Kubernetes establishes a “default” namespace for unspecified resources. You can add namespaces using the Kubernetes API or kubectl.
Namespaces are used for:
- Multitenancy: Kubernetes namespaces can segregate resources and prevent interference between teams or users.
- Development and testing: Namespaces simplify application lifecycle management by creating discrete contexts for development, testing, and staging.
- Resource management: Namespaces can enforce resource quotas and restrictions, preventing applications from exceeding their allotments and preventing cluster resource contention.
Q.7 What is a Kubernetes node?
Nodes run containerized apps in Kubernetes. The Kubernetes control plane runs one or more pods on each node.
Nodes operate containers and provide CPU, memory, and storage. Nodes are physical or virtual machines connected to a network and storage system.
Kubernetes arranges pods on nodes with enough resources. Docker, containerd, or CRI-O run on each node to manage containers.
The Kubernetes API lets nodes receive pod management instructions and report status and resource use to the control plane.
Kubectl and dashboards can manage and monitor nodes. These tools let you view cluster node information, monitor resource utilisation, and scale nodes up or down.
Q.8 What is a Kubernetes cluster?
A cluster in Kubernetes is a group of nodes and other resources that run containerized applications. Control plane nodes manage the cluster and schedule workloads, while worker nodes run containers.
etcd, kube-scheduler, and kube-controller-manager make up the control plane. These components coordinate cluster state, workload scheduling, and API responses.
Workers run containers and provide CPU, memory, and storage. Kubernetes runtime environments like Docker or containerd manage containers on worker nodes.
Pods, Deployments, and Services are defined when you deploy an application to a Kubernetes cluster. Kubernetes runs the programme on the right nodes and scales it up or down based on demand.
Kubectl, Kubernetes dashboard, and third-party administration solutions can manage on-premises or cloud-deployed Kubernetes clusters.
Q.9 What is a Kubernetes master?
The master node maintains the control plane components that schedule and manage workloads in Kubernetes.
The control plane components include:
- Kubernetes API server: The control plane’s front-end. The Kubernetes API lets other components communicate and manage the cluster.
- etcd: This distributed key-value store stores cluster configuration data. It stores pod and service locations and control plane component configuration data.
- kube-scheduler: Schedules workloads on worker nodes. It considers resource availability and workload when scheduling.
- kube-controller-manager: This component ensures that the cluster state matches the required state. A set of controllers monitors the cluster and adjusts as needed.
The master node is usually configured as a highly available cluster with many control plane nodes for redundancy and fault tolerance. To achieve high availability and consistency, each master node communicates with the others.
Q.10 What is a Kubernetes worker node?
A worker node (or minion) in Kubernetes runs containers and provides computational resources for application workloads.
The control plane components on the master node oversee worker nodes running Kubernetes runtime environments like Docker or containerd (s). The master nodes tell the worker node which containers to run and where.
The worker node manages containers and provides resources using multiple components:
- Kubelet: Each worker node executes this agent to receive container commands from the master nodes. The Kubelet starts, stops, monitors, and reports container status to the master node(s).
- Container runtime: This programme runs containers on worker nodes. Kubernetes supports Docker, containerd, and others.
- Kube-proxy: Each worker node’s network proxy manages network communication between the node’s containers and the cluster.
Each worker node has CPU, memory, and storage for containers to use. The Kubernetes Resource Management API and Resource Quotas functionality manage these resources.
Q.11 What is a Kubernetes replica set?
A replica set in Kubernetes controls a set of identical pods and keeps a defined number of pod replicas active.
The replica set creates or deletes pods to maintain the desired number of copies. It can roll upgrades, restarts, and scale replicas by labelling the pods it manages.
Key replica set features:
- Pod templates: The replica set configures pods using pod templates. The template can include container image, environment variables, and replica count.
- Label selectors: The replica set identifies its pods via label selectors. Label selectors like app=web can filter pods.
- Scaling: The replica set can increase or decrease replicas based on application demands. Manually or automatically based on CPU or memory consumption.
- Rolling updates: The replica set can be used to update the application by replacing old pods with new ones. This reduces downtime and ensures application availability.
Q,12 What is a Kubernetes stateful set?
StatefulSets in Kubernetes provide pod ordering and uniqueness for stateful applications. It helps applications with reliable network identities, persistent storage, and ordered deployment and scaling.
StatefulSets differ from ReplicaSets:
Ordered deployment: StatefulSets deploy pods in a certain sequence with unique hostnames based on reliable network identities. This ensures that stateful programmes start and end pods in order.
StatefulSet pods have distinct network identities based on stable DNS hostnames. This lets other pods and services use the pod’s hostname instead of its changing IP address.
Persistent storage: StatefulSets support pod-attached volumes or persistent drives. Even if the pod is moved to a new node, data is saved and retrieved from the same place.
StatefulSet characteristics include:
Scaling: Like other Kubernetes objects, StatefulSets can be scaled up or down, but in a precise order to retain application state.
Rolling updates offer controlled and ordered application updates with StatefulSets.
StatefulSets automatically recover failed pods. Kubernetes automatically reschedules failed pods on other nodes.
Q.13 What is a Kubernetes daemon set?
DaemonSets in Kubernetes guarantee that a collection of pods runs on every cluster node. It helps run system daemons and other node-wide functions.
A DaemonSet runs a pod on each cluster node and monitors its health. The DaemonSet automatically produces or deletes pods to maintain the specified number of pods on each node when a node is added or removed.
Key DaemonSet features:
- Automated placement: DaemonSets automatically put a pod on every cluster node to ensure that the given service or daemon is functioning.
- Node-awareness: DaemonSets automatically create or delete pods as nodes join or leave the cluster.
- Rolling updates: DaemonSets provide controlled, incremental pod updates across the cluster.
- Node labelling: DaemonSets deploy pods on nodes labelled. This offers fine-grained control over the service or daemon’s nodes.
Q.14 What is a Kubernetes job?
Job objects in Kubernetes handle task execution. Jobs conduct one-time activities like backups, batch processes, and containerized scripts.
Each pod executes one instance of the specified container in a Job. To obtain the target number of pod completions, the Work object tracks pod progress and automatically creates new pods if any fail.
Key Kubernetes Job features:
- Parallelism: Jobs can run numerous pods simultaneously to do tasks rapidly.
- Completions: A Job can specify the number of successful completions before terminating.
- Retries: If a pod fails, the Job can automatically retry the job a set number of times.
- CronJobs: Like Linux’s cron jobs, Kubernetes’ CronJob lets a Job be scheduled to execute at specific intervals.
Q.15 What is a Kubernetes cron job?
A CronJob in Kubernetes lets you schedule jobs like a Unix cron job. CronJobs generate Job objects at defined intervals using cron-like syntax. Backups, data cleanup, and batch procedures can benefit from this.
CronJobs include:
- Schedule: A cron-like schedule for Job execution.
- Job Template: A template that specifies the Job, including the container image, command, and other configuration information.
- Concurrency Policy: How CronJob handles overlapping jobs. Allow, forbid, or replace.
- Beginning Deadline: The last day to start the job.
- Successful Job History Limit: Number of successful jobs to keep.
- Failure Job History Limit: Number of failed jobs to maintain.
Q.16 What is a Kubernetes persistent volume?
A Persistent Volume (PV) in Kubernetes stores data independently of the pod’s lifespan. PVs are physical discs attached to Kubernetes nodes that pods can use.
A cluster administrator creates a PV for developers to store data persistently. Size, access modes, and storage class describe a PV. These factors determine the pod’s PV use.
PVs are manufactured without pods. PVCs are needed to bind PVs to pods. A pod’s PVC specifies storage size and access mechanisms. Kubernetes searches for a matching PV after creating a PVC. The PVC is linked to a compatible PV, and the pod can store data on the PV.
PVs function with local, network, and cloud storage. Kubernetes supports plugins for many storage systems to construct PVs backed by the storage system.
Q.17 What is a Kubernetes storage class?
StorageClasses in Kubernetes define Persistent Volume characteristics (PVs). Developers can design storage classes with varied performance and capabilities and assign them to their apps using a StorageClass.
Based on characteristics, StorageClasses dynamically provision PVs. Kubernetes will use the matching StorageClasses when a pod creates a PVC to seek storage. Created PVs will have StorageClass attributes.
Storage Classes include:
- Provisioner: The storage provisioner that creates the PV.
- Parameters: PV creation parameters.
- Reclaim Policy: What happens to the PV when the PVC is erased. Keep, Delete, or Recycle.
- Volume Binding Mode: How the PV is bound to a node. Immediate or WaitForFirstConsumer.
Kubernetes StorageClasses offer flexibility. They let developers design storage classes with various features and performance and assign them to their applications. Developers can request storage resources for their apps without cluster administrator intervention using StorageClasses.
Q.18 What is a Kubernetes config map?
ConfigMaps in Kubernetes store configuration data as key-value pairs. Developers can manage configuration data independently of the application lifecycle.
ConfigMaps can hold configuration data like environment variables, command-line arguments, and configuration files. Pods can configure their environment and behaviour using ConfigMap data.
Developers can use cluster administrator-created ConfigMaps. Manually or automatically construct a ConfigMap. ConfigMaps are Kubernetes resources that pods can access via environment variables or mounted volumes.
ConfigMaps can be modified runtime without restarting pods. Kubernetes updates pods using ConfigMaps automatically.
Q.19 What is a Kubernetes secret?
Secrets in Kubernetes store and handle sensitive data including passwords, tokens, and certificates. Secrets store and manage confidential data like ConfigMaps.
Secrets, like ConfigMaps, are produced by the cluster administrator and used by developers in their code. Manually or automatically create secrets. Secrets are Kubernetes resources that pods can access via environment variables or mounted volumes.
Only authorised users and programmes can decrypt secrets at rest. They can secure access to databases, APIs, and critical configuration data.
Runtime secrets can be updated without restarting pods. Kubernetes updates pods using Secrets automatically.
Q.20 What is a Kubernetes ingress?
In Kubernetes, an Ingress API object manages external access to cluster services. It routes external traffic based on host name and URL path to the appropriate service as a gateway.
Ingress rules route incoming traffic. Each rule has a host name, URL paths, and a service to route traffic to. Several Ingress rules might correlate distinct host names and URL paths with different services.
Ingress requires an Ingress controller on a Kubernetes cluster. The Ingress controller implements Ingress object rules and routes incoming traffic to the relevant service.
Ingress allows flexible and scalable external access to Kubernetes services. Developers can define and manage external traffic routing rules independently of the application lifetime.
Q.21 What is a Kubernetes network policy?
Network policies in Kubernetes define how pods can communicate with one other and other network endpoints. It regulates cluster pod and service traffic.
Network policies can establish fine-grained security policies for microservices application communication. It can restrict service traffic depending on source and destination pods, protocol, and ports.
Kubernetes API objects NetworkPolicy, NetworkPolicyList, and NetworkPolicyPeer define network policies. Kubernetes command-line tools and API clients generate and manage them.
The Kubernetes network plugin regulates network traffic between cluster components. The plugin automatically configures network rules to filter traffic according to network policies.
Q.22 What is a Kubernetes operator?
An operator in Kubernetes defines custom resources and controllers to automate the deployment and maintenance of complicated applications or services. Operators encapsulate operational knowledge of an application or service and automate its lifecycle management.
Operators are constructed utilising the Kubernetes API and programming languages like Go or Python. They define custom resources that extend the Kubernetes API and controllers that govern their lifespan. Operators can automate deploying, scaling, updating, and monitoring complex applications and services.
In a Kubernetes cluster, a database operator can automate database service deployment and management. The operator would design specific database service resources, such as configuration, size, and scaling policies, and develop controllers to manage their lifetime, such as providing new instances, scaling them up or down, and updating the software version.
Operators simplify the management of complicated applications or services in a Kubernetes cluster, making them easier to deploy and operate at scale. Developers can focus on application operational expertise rather than deployment and management issues.
Q.23 What is a Kubernetes custom resource definition?
A custom resource definition (CRD) allows Kubernetes to define new custom resources that can be handled using its tools and APIs. Kubernetes custom resources represent new objects with unique features and behaviour.
Users can design their own objects and controllers without modifying the core Kubernetes software using custom resources. This lets you define and manage resources beyond pods, services, and deployments.
Bespoke resource schemas include properties, validation rules, and default values. The regular Kubernetes API can handle bespoke resources, and custom controllers can manage their lifecycles.
CRDs can represent new application workloads like batch processing jobs or machine learning models. After defining the CRD, users can create, update, and delete resource instances using the Kubernetes API. Bespoke controllers can supply new instances, scale them up or down, and check their health.
Custom resource definitions enable Kubernetes API extension and platform customization. They allow users to define additional objects and controllers to manage their infrastructure and apps without modifying the Kubernetes source.
Q.24 What is a Kubernetes API server?
Helm charts install and manage applications on Kubernetes clusters. YAML files define Kubernetes resources including deployments, services, and config maps, as well as application-specific resources like databases, caches, and messaging queues.
Helm charts simplify Kubernetes application packaging and distribution by standardising deployment methods and configurations. They let developers and operators launch complex applications with all their dependencies and parameters rapidly.
Helm charts are installed, upgraded, and managed on Kubernetes clusters using Helm’s command-line interface. Helm allows templating to adjust chart values and setups for different contexts and use cases.
A Helm chart may deploy a WordPress application, MySQL database, and persistent volume. The chart would include Kubernetes resource YAML files and application configuration templates and scripts.
The Helm chart can be shared and used to install the same application on different Kubernetes clusters. Helm’s command-line interface makes Kubernetes deployment and management of complicated applications straightforward.
Q.25 What is a Kubernetes scheduler?
The Kubernetes scheduler assigns pods to worker nodes. When a pod is created or terminated, the scheduler chooses a node based on resource availability, node capacity, and pod requirements.
The Kubernetes scheduler is flexible, allowing unique scheduling policies and algorithms. The scheduler chooses pod nodes by priority by default. It can employ complex scheduling policies based on node labels, pod affinity, and anti-affinity rules.
While scheduling a pod, the scheduler evaluates resource requirements, resource availability on each node, and user limits. Based on these characteristics, it then schedules the pod to execute on the best node.
The scheduler constantly monitors the cluster and adjusts pod assignments to maintain the desired system status. The scheduler will reschedule pods to other cluster nodes if a node becomes unavailable or resource limitations change.
Q.26 What is a Kubernetes controller manager?
The controller manager in Kubernetes manages the cluster controllers. Controllers monitor the cluster and make changes to maintain the desired condition of the system.
The controller manager manages the replication, replica set, deployment, and stateful set controllers. Each controller ensures the cluster has the specified number of pod replicas.
The controller manager handles events and triggers actions. The controller manager will start a new pod if a pod fails or becomes unresponsive.
The Kubernetes master node’s controller manager uses the API server to get the cluster’s current state. It periodically compares the cluster’s status to the system’s desired state and takes corrective action if necessary.
Q.27 What is a Kubernetes etcd?
Etcd stores Kubernetes cluster configuration data. It stores all Kubernetes object configuration data, including pods, services, and nodes.
etcd is a fault-tolerant datastore that provides consistent and reliable access to configuration data. It elects a leader from etcd nodes to handle datastore write operations. The cluster’s followers replicate the leader’s data to maintain consistency.
Etcd data is hierarchical, with each key-value pair representing a configuration item. Kubernetes retrieves and updates cluster configuration data from etcd.
Q.28 How does Kubernetes handle scaling?
Kubernetes has numerous scaling strategies to manage different traffic and demand levels. Kubernetes scales:
- Horizontal Pod Autoscaling (HPA): HPA scales pod replicas based on CPU use or other metrics. This lets the programme handle more traffic and load without manual intervention.
- Vertical Pod Autoscaling (VPA): VPA optimises CPU and memory resources based on pod resource use patterns. The application has enough resources to handle its task.
- Cluster Autoscaling: Cluster Autoscaling adds or removes nodes based on resource need. This optimises resource use and guarantees the cluster can manage the workload.
- Node Autoscaling: Node Autoscaling scales cluster nodes based on resource requirements. This optimises resource use and guarantees the cluster can manage the workload.
Q.29 What are some common challenges when using Kubernetes?
Kubernetes challenges include:
- Complexity: Kubernetes is difficult to set up and manage, especially for businesses without a DevOps team or containerization and orchestration knowledge.
- Resource Management: To avoid overprovisioning and inefficiency, Kubernetes requires careful resource management.
- Networking: Multi-cluster and hybrid cloud setups make Kubernetes networking difficult. Kubernetes networking involves knowledge of network regulations, service meshes, and load balancing.
- Security: Kubernetes cluster security needs container, network, and identity and access management skills.
- Monitoring and logging: Kubernetes clusters are complicated, have many components, and require real-time performance and availability insights.
- Upgrades and updates: Kubernetes cluster upgrades must be carefully planned and executed to minimise downtime and assure component compatibility.
Q.30 What is a Kubernetes operator, and how does it differ from a regular controller?
Kubernetes Operators are custom controllers that expand the API to manage complicated stateful applications. Operators employ domain-specific knowledge to deploy, scale, backup, and recover applications using bespoke resources to represent applications and their dependencies.
Operators can manage more sophisticated applications than normal controllers. Operators are application-specific and provide sophisticated capabilities, unlike generic controllers. Operators automate laborious, error-prone, or time-consuming database cluster upgrades and backups.
Operators monitor and manage application state using Kubernetes APIs. They can be created in Go, Python, or Java and managed via Ansible, Helm, or Puppet.
Q.31 Can you explain how Kubernetes handles rolling updates and rollbacks?
Kubernetes’ deployment controller maintains a deployment’s desired state and guarantees that it matches the actual state for rolling updates and rollbacks.
Kubernetes gradually installs a new application version during a rolling upgrade. Procedure:
- New application versions get a replica set from the deployment controller.
- The deployment controller gradually adds replicas to the new replica set and removes them from the old replica set until all replicas are running the new version.
- The old replica set is erased after all replicates are running the new version. Our rolling update technique minimises application downtime and detects and fixes issues before updating the entire deployment.
Kubernetes can rollback if an issue occurs during rolling updates. Process:
- The deployment controller recreates the prior application’s replica set.
- The deployment controller gradually raises the old replica set while decreasing the new replica set until all replicas are running the older version.
- The new replica set is destroyed after the prior version is fully deployed. In case of problems during the update, this rollback mechanism allows the app to be turned back rapidly.
Q.32 What are Kubernetes Custom Resource Definitions (CRDs), and how can they be used to extend Kubernetes functionality?
Custom Resource Definitions (CRDs) allow Kubernetes to add new resources that can be managed like built-in ones. CRDs let users create API objects and controllers.
CRDs make application-specific resources. If an application needs a resource not available in Kubernetes, a CRD can describe it. Users can construct instances of the CRD in their Kubernetes cluster, and its controllers can manage them.
CRDs can coordinate Kubernetes resource creation and management for complicated applications. Users can manage the entire application as a resource by establishing a CRD that defines the intended state.
CRDs manage Kubernetes cluster databases. A CRD can represent a database instance, including controllers to create and configure its pods, services, and persistent volumes.
Q.33 How does Kubernetes handle resource quotas and limits, and what are some best practices for setting them?
Kubernetes allows pod or namespace resource quotas and limits. Resource quotas limit a namespace’s CPU, memory, and other resources, while resource limits limit a container or pod’s.
Kubernetes has numerous ways to handle resource restrictions. Examples:
- Requests and Limits: Requests are the least resources a container or pod requires to function, while limits are the maximum. If a container or pod exceeds its limits, Kubernetes terminates it.
- Horizontal Pod Autoscaler (HPA): The HPA scales deployment replicas based on pod CPU or memory use.
- Vertical Pod Autoscaler (VPA): Based on pod usage, the VPA optimises resource consumption by adjusting resource requests and restrictions.
Kubernetes resource quota and limit best practices:
- Monitoring resource use: To set quotas and limitations correctly, you must regularly check pod and application resource utilisation.
- Establishing realistic quotas and limits: Set quotas and limits that match your application’s resource needs yet allow for traffic surges.
- Requesting and limiting: Establish reasonable pod container demands and restrictions. Request resources for containers and set limitations to prevent them from using too much.
- HPAs and VPAs: Employ horizontal and vertical pod autoscaling to automatically modify replicas, resource demands, and restrictions according on application consumption.
Q.34 What is a Kubernetes StatefulSet, and in what scenarios would you use it?
Stateful apps are managed via Kubernetes StatefulSets. It guarantees each Pod’s unique identification and ordering.
StatefulSets are used for applications that need solid network identities or storage, such as databases, messaging queues, and key-value stores. A StatefulSet’s Pods have a consistent hostname and persistent storage, so the application’s state can be maintained even if the Pod is destroyed or rescheduled.
StatefulSets’ ordered scaling and rolling updates minimise application downtime during updates. StatefulSets can also be utilised with headless services to discover Pods by their stable network identity.
Q.35 What are some strategies for scaling Kubernetes clusters horizontally and vertically, and what are the trade-offs of each approach?
Horizontal scaling in Kubernetes adds or removes nodes to meet application demand. Methods include:
- Cluster Autoscaling: Nodes are added or removed based on resource demand. Cluster autoscaling uses CPU, memory, or custom metrics.
- Pod Autoscaling: CPU utilisation or custom metrics determine the number of pods in a deployment or replica set. Pod autoscaling can ensure that enough pods are running to meet application demand.
- Vertical scaling, on the other hand, adjusts cluster node resources. Increase or decrease a node’s CPU or RAM. Vertical scaling methods:
- Node-Level Scaling: Adjusting node resources manually. Kubernetes API or cloud provider management console.
- Container-Level Scaling: Adjusting node resources for individual containers. Kubectl or Docker Swarm can achieve this.
Q.36 Can you explain how Kubernetes handles networking, including pod-to-pod communication and external connectivity?
Kubernetes uses multiple components to network.
Kubernetes networking revolves around Pods, the smallest deployable unit. Containers in pods share a network namespace and IP address. This implies Pod containers can communicate using localhost.
Kubernetes employs a container networking interface (CNI) plugin to construct a cluster-wide virtual network for Pod communication. The kubelet on each node configures the CNI plugin and Pod network interfaces.
Services also give Pods a consistent IP address and DNS name. Services allow Pods to communicate with external clients using various load balancing strategies.
Network Policies can be used to control access to Kubernetes Services and Pods based on IP addresses, ports, and protocols.
Q.37 How does Kubernetes handle persistent storage, and what are some best practices for managing data in a Kubernetes environment?
Kubernetes offers persistent storage management options. PVs and PV Claims are a popular method (PVCs). PVCs are pod storage requests, while PVs are cluster storage resources.
Kubernetes requires a storage class to define the PVs’ storage type. Storage class attributes include type (local, network-attached), access mode (read-only, read-write), and reclaim policy (e.g., retain, delete).
Kubernetes chooses a PV that matches the storage class and other PVC requirements when a pod requests a PVC. The pod can access storage via the PVC after the PV is linked to it.
Kubernetes data management best practises include:
- Each persistent pod needs a PVC.
- Utilize application-specific storage classes.
- Prevent data loss and corruption by configuring and monitoring your storage resources.
- Stateful applications like databases need stateful sets for unique identities.
- Protect your data with data backup and catastrophe recovery.
- Encrypt sensitive data and restrict access.
Q.38 What is Kubernetes federation, and how can it be used to manage clusters across multiple regions or clouds?
Kubernetes Federation makes it easier to deploy and manage applications across many regions and cloud providers by managing multiple clusters as a single entity. The federation control plane manages several Kubernetes clusters and enforces networking, security, and resource allocation standards.
Kubernetes federation lets administrators establish global configurations and deploy them across many clusters, simplifying environment consistency. This is important for multi-cloud or multi-region deployments where applications must be deployed across geographically distant clusters.
A federation control plane can manage numerous Kubernetes clusters for federation. Global configurations and policies are then applied to all managed clusters. A federated API server in Kubernetes federation lets administrators query and manipulate resources across several clusters via a single interface.
Kubernetes federation makes it easy to deploy and manage apps across numerous clusters without manually configuring each one. This can reduce distributed environment operational expenses and make scaling applications and services easier.
Managing a federated Kubernetes system is complicated and requires careful planning and design. Companies should evaluate network latency, data transfer costs, and Kubernetes federation management resources and knowledge.
Q.39 What is Kubernetes security, and what are some best practices for securing a Kubernetes environment?
Kubernetes security protects an environment from threats. Kubernetes security best practises include:
- RBAC controls Kubernetes resource access. RBAC lets administrators set roles and permissions for cluster users, groups, and services.
- Network policies manage pod traffic and cluster access. Administrators can set network policies for cluster traffic.
- Employ TLS to encrypt cluster component communication.
- Before deploying to the cluster, scan trustworthy container images for vulnerabilities.
- Secrets and ConfigMaps store passwords, API keys, and certificates.
- Update Kubernetes components and dependencies regularly to correct security vulnerabilities.
- Pod security regulations enforce cluster pod security.
- Monitor the cluster for security breaches and act quickly.
- To discover and address Kubernetes security concerns, use a dedicated tool or service.
Q.40 What are some of the most important differences between Kubernetes and other container orchestration platforms like Docker Swarm or Mesos?
Kubernetes, Docker Swarm, and Apache Mesos all orchestrate containers, but they differ.
Kubernetes is the most popular container orchestration platform, with a huge and active user and contributor community. Kubernetes manages containerized applications with automated scaling, rolling updates, load balancing, and more. It’s flexible. Declarative configuration and infrastructure-as-code make Kubernetes suitable for complex and dynamic contexts.
Docker Swarm is a lighter, Docker-integrated orchestration platform. Swarm has fewer features and a simpler architecture than Kubernetes, simplifying the user experience. For simpler deployments, Swarm is easier to set up and utilise than Kubernetes.
Large-scale deployments use Apache Mesos, a scalable and adaptable distributed system platform. Mesos is more complicated and difficult to set up and operate than Kubernetes or Swarm, but it manages distributed applications well.
Q.41 Can you explain how Kubernetes handles load balancing, and what are some best practices for configuring load balancing in a Kubernetes environment?
Kubernetes offers service and ingress load balancing.
Kubernetes services load balance pods by providing a stable endpoint. Round-robin, IP hash, and session affinity help balance service load. IP hash load balancing distributes requests by source IP address, while round-robin load balancing distributes pods sequentially. Session affinity routes requests from the same client to the same pod.
Kubernetes ingresses expose HTTP and HTTPS routes from outside the cluster to cluster services for ingress load balancing. Ingress can route traffic by path, hostname, or header.
Kubernetes load balancing best practices:
- Service load balancing for internal traffic and ingress for external traffic.
- Session affinity service load balancing directs related requests to the same pod.
- Nginx, HAProxy, or Traefik are Kubernetes-compatible load balancers.
- Use Istio or Linkerd for advanced load balancing and traffic management.
Q.42 How does Kubernetes handle secrets management, and what are some best practices for securing sensitive data in a Kubernetes environment?
Kubernetes manages “secrets”—sensitive data like passwords, certificates, and tokens—built-inly. A secret is an object that needs to be safely saved and transferred to a container. It may contain a password or token. Secrets can be mounted as volumes or provided as environment variables to containers.
Kubernetes encrypts secrets at rest and in transit, limits access to authorised users, and rotates secrets to reduce chance of compromise. Kubernetes, command-line, and third-party tools can manage secrets.
Kubernetes secrets should be secured using these methods:
- Hard-coding secrets in application code or configuration files is bad.
- Instead of sending secrets as command-line arguments, use volume mounts or environment variables.
- Limit hidden access to those who need it using the least privilege concept.
- Access secrets with Kubernetes RBAC.
- Avoid compromise by rotating secrets.
- Employ a secure backend like Kubernetes secrets or HashiCorp Vault.
Q.43 What is a Kubernetes custom controller, and how can it be used to extend Kubernetes functionality?
A Kubernetes custom controller extends the control plane by automating custom resource management. Custom controllers can automate complicated operational processes like resource creation and business logic using the Kubernetes API.
Bespoke controllers can enhance Kubernetes functionality. They can automate bespoke resource development and pod scheduling logic. Custom controllers can implement complex deployment techniques like blue-green or canary deployments, application-specific policies, and business logic.
Custom controllers may monitor and respond to Kubernetes API changes, making them powerful. Custom controllers can automatically react to system changes like resource creation or configuration data changes.
Developers utilise Kubernetes client libraries like Go or Python to create bespoke controllers. These libraries simplify Kubernetes API interaction and allow advanced logic and automation for specialised resource management.
Q.44 Can you explain how Kubernetes handles service discovery and routing, and what are some best practices for configuring Kubernetes services?
A Kubernetes service is an abstraction layer that gives a set of pods the same IP address and DNS name. These services require discovery and routing.
Kubernetes groups pods by function, such as web servers or database servers, using labels. Then a service represents the pods. Other services and clients can reach the pods using the service’s stable IP address and DNS name. Kubernetes uses a load balancing mechanism to route requests to the service IP address and port to one of the pods.
ClusterIP, NodePort, LoadBalancer, and ExternalName are Kubernetes services. ClusterIP is the default service for cluster communication. NodePort provides the service on a cluster node port for external access. ExternalName generates a DNS name for an external service, while LoadBalancer builds an external load balancer.
Service type, port numbers, and selectors for pod routing must be considered when configuring Kubernetes services. Services should be configured using well-defined port numbers, pod labels, and service accounts to limit access. Use Kubernetes Ingress to govern external access to services and configure health checks to assure service health.
Q.45 How does Kubernetes handle resource allocation and scheduling, and what are some best practices for optimizing resource utilization in a Kubernetes environment?
Kubernetes utilises a declarative approach to resource allocation and scheduling, where users declare the intended cluster state and the scheduler attempts to match it.
Each pod’s resource requests and limits should be optimised to maximise resource use. Resource requests tell the scheduler the pod’s minimal resources, whereas resource limitations tell the Kubernetes runtime its maximum.
The Kubernetes scheduler’s scheduling policies should also be considered. The scheduler distributes pods across cluster nodes using a round-robin policy by default, however spread, binpack, and random may be better depending on the workload.
Kubernetes autoscaling can dynamically increase or reduce the number of replicas of a deployment or StatefulSet based on CPU or memory usage to improve resource efficiency.
Q.46 What is Kubernetes ingress, and how can it be used to manage external access to Kubernetes services?
Kubernetes Ingress manages external access to services. It routes external traffic to the cluster service based on ingress resource rules.
Hence, an ingress manages external access to a Kubernetes cluster, serving as a gateway to its services. It handles external access, traffic routing, SSL termination, and load balancing.
Configure an ingress controller to implement the routing and traffic management rules in the ingress resource before using an ingress. Nginx, Traefik, and Istio are Kubernetes ingress controllers.
After installing and configuring an ingress controller, you can establish an ingress resource to set service external access rules. This usually entails setting the hostname or IP address to listen on and routing traffic to the right service based on URL routes or other criteria.
Q.47 What is Kubernetes Helm, and how can it be used to manage complex Kubernetes deployments?
Kubernetes Helm, a Kubernetes package manager, simplifies the deployment and maintenance of complicated applications. Helm lets charts install, upgrade, and remove Kubernetes applications.
A Helm chart is a set of YAML files that outline the Kubernetes resources needed to launch an application. Deployment configurations, services, ingresses, and other Kubernetes objects needed to operate an application can be included.
Helm lets developers package their apps into charts and distribute and install them on any Kubernetes cluster. This makes sophisticated application deployment, configuration sharing, and human error reduction easier.
Helm enables application versioning and rollbacks, making it easy to upgrade and revert. Helm also has a huge and active community that maintains a large repository of charts for common applications.
Q.48 Can you explain how Kubernetes handles container networking, and what are some best practices for configuring Kubernetes networking?
Kubernetes streamlines application deployment, scalability, and management. Container networking, which lets containers talk to each other and outside services, is a key Kubernetes feature.
Kubernetes’ network plugin design lets users pick the optimal networking option. Popular network plugins:
- Flannel, an easy-to-use network plugin for Kubernetes, provides a virtual network overlay.
- Calico, a scalable network plugin for policy enforcement and security.
- Weave Net – a network plugin for fast container-service communication.
Kubernetes uses CNI to manage container networking regardless of network plugin. Container runtimes configure network interfaces and routes using the CNI API.
Kubernetes creates a network namespace for each pod and assigns each container a unique IP address. Kubernetes supports service discovery and load balancing so containers can communicate with pods and services outside the cluster using their IP addresses.
Best practises for Kubernetes networking include:
- Choose a suitable network plugin. Choose the network plugin that meets your needs.
- Flatten network topologies whenever possible. NAT and complex network topologies can slow performance and make troubleshooting harder.
- Network policies manage pod traffic. Network policies govern pod traffic flow and offer security.
- Monitor network performance. Use Kubernetes Dashboard, Prometheus, or Grafana to monitor network traffic and performance to spot anomalies.
- Check network connectivity. To ensure network functionality, test pod-service connectivity often.
Q.49 What is Kubernetes Multi-Cluster, and how can it be used to manage multiple Kubernetes clusters?
Kubernetes Multi-Cluster allows you to manage numerous clusters from a single control plane. Kubernetes Multi-Cluster makes it easier to grow and deploy applications in a distributed environment by managing and orchestrating applications across several clusters.
Kubernetes Multi-Cluster can handle many clusters in several ways:
- Federated clusters: Manage numerous Kubernetes clusters as a single logical unit with federated clusters. This technique lets you deploy apps and services across different clusters and manage them as if they were in a single cluster.
- Shared control plane: You can install multiple Kubernetes clusters utilising the same control plane in a shared control plane scenario. This method simplifies application deployment and management by providing a centralised management interface for all clusters.
- Replicated control plane: With a replicated control plane, you can deploy numerous Kubernetes clusters with identical control planes. This method gives your clusters excellent availability and redundancy, making it easy to maintain and scale your applications.
To use Kubernetes Multi-Cluster, you must configure a federation control plane, cluster API server, and cluster registry. Once these components are in place, you may construct and manage clusters using Kubernetes API and kubectl commands.
Kubernetes Multi-Cluster has several advantages:
- Easier management: Kubernetes Multi-Cluster lets you deploy and manage apps across several clusters.
- Scalability: Kubernetes Multi-Cluster lets you extend applications over many clusters to manage rising traffic and demand.
- Increased reliability: Kubernetes Multi-duplicated Cluster’s control planes and centralised management boost cluster resilience and availability.
Q.50 How does Kubernetes handle stateful applications, and what are some best practices for managing stateful applications in a Kubernetes environment?
Kubernetes now supports stateful apps. Stateful programmes store data persistently and cannot be scaled horizontally.
StatefulSets, a controller in Kubernetes, provide pods distinct identities, ordered deployment and scalability, and stable network identities. StatefulSets guarantee stable, unique storage.
Stateful application management best practises in Kubernetes:
- StatefulSets manage stateful applications in Kubernetes. StatefulSets ensures stateful application deployment, scaling, and management.
- Persistent volumes are essential for stateful applications. Persistent volumes in Kubernetes can be used with StatefulSets to keep data persistent after a pod restart.
- Headless services help manage stateful applications in Kubernetes. Stateful applications need headless services to access each StatefulSet pod by its network identity.
- Stateful application patterns control data consistency, availability, and durability. To run stateful apps correctly, employ Kubernetes-specific stateful application paradigms.
- Backup your data: Like with any programme, backing up your data prevents data loss in the event of a failure. Backup and restore stateful application data regularly.
Q.51 Can you explain how Kubernetes handles rolling updates and rollbacks, and what are some best practices for managing Kubernetes deployments?
For application availability and reliability, Kubernetes offers numerous deployment update and rollback techniques. Rollbacks let you revert to a prior version of your software if it doesn’t work, while rolling updates let you publish new versions without downtime.
Rolling updates and rollbacks in Kubernetes:
- Rolling updates: Kubernetes lets you deploy new app versions without downtime. To keep the programme running, rolling updates gradually replace old pods with new ones. If a new pod fails to start during the rolling update, Kubernetes rolls back to the previous version.
- Rollbacks: If the new version has flaws, Kubernetes lets you roll back to the prior version. Rollbacks undo the update and restore the application to its prior state.
Best practises for managing Kubernetes deployments:
- Use Kubernetes Deployments to declaratively manage apps and support rolling updates and rollbacks. To manage updates and rollbacks, use Deployments.
- Canary Deployments: Before going out to all users, test new software versions with a small percentage of users. Before releasing to all users, utilise Canary Deployments to test the new app version.
- Monitor your deployments with Kubernetes’ liveness and readiness probes. Monitor your deployments using these tools.
- Use ConfigMaps and Secrets to store configuration data and sensitive information like credentials instead of hard-coding it in the application code. It enhances security and simplifies configuration management.
Employ Horizontal Pod Autoscaling to automatically scale your application based on CPU consumption or configurable metrics. Your application can handle more traffic and burden this way.
Q.52 What is Kubernetes Service Mesh, and how can it be used to manage microservices in a Kubernetes environment?
Kubernetes Service Mesh enables service-to-service connectivity. Traffic management, service discovery, security, and observability help manage microservices in Kubernetes.
Kubernetes Service Mesh is usually implemented using Istio, Linkerd, or Consul. These systems help developers manage Kubernetes microservices more efficiently.
In Kubernetes, Service Mesh can manage microservices:
- Traffic management: Kubernetes Service Mesh may load balance, circuit break, and transfer traffic. These features help developers control microservice traffic and keep the application available and responsive.
- Service discovery: Kubernetes Service Mesh lets microservices discover and communicate with other services. This simplifies application microservice management.
- Security: To secure microservices, Kubernetes Service Mesh provides encryption, authentication, and authorisation. These features encrypt data in transit and restrict access to sensitive services.
- Observability: Kubernetes Service Mesh provides monitoring, logging, and tracing to help developers diagnose microservice issues. These capabilities simplify application management and assure smooth operation.
Q.53 How does Kubernetes handle container runtime security, and what are some best practices for securing container runtimes in a Kubernetes environment?
Kubernetes has multiple ways to secure container runtimes. Container runtime security protects sensitive data and ensures the programme runs securely. Kubernetes secures container runtimes:
- Secure container images: Kubernetes deploys apps using container images. Secure and vulnerability-free photos are vital. Image scanning and policy enforcement in Kubernetes provide secure image use.
- Resource isolation: Kubernetes isolates containers so they only use the resources they need. Its isolation secures critical data and resources.
- Administrators can set pod security policies in Kubernetes. Security context, network policies, and volumes secure pods.
- Role-based access control: Kubernetes restricts resource access with RBAC. RBAC restricts sensitive resource access to approved users, decreasing risk.
- Container runtime security tools: Kubernetes offers seccomp, AppArmor, and SELinux to restrict system calls and activities for containers. These utilities secure containers.
Kubernetes container runtime security best practises:
- Utilize trusted container images with no vulnerabilities.
- Define pod security policies to safeguard pods.
- Restrict Kubernetes resource access via RBAC.
- Enable container runtime security techniques like seccomp, AppArmor, and SELinux to limit system calls and operations.
- Scan and update containers regularly to keep them secure.
Q.54 What is Kubernetes network policy, and how can it be used to manage network traffic in a Kubernetes environment?
Kubernetes Network Policy lets you regulate network traffic to and from your application’s pods. It controls network segmentation and pod, namespace, and external network connectivity.
Kubernetes Network Policy lets you allow or prohibit network traffic depending on source IP address, destination IP address, protocol, and port. This enables a zero-trust security approach and application protection.
Network policies can regulate entrance and egress traffic at the pod, namespace, or cluster level. For instance, you can restrict traffic to a port or IP address.
Cluster Kubernetes network plugins enforce network restrictions. Make sure your network plugin supports network policies.
Kubernetes Network Policy tips:
- Only allow required traffic to apply the principle of least privilege.
- Label pods or namespaces for network policies.
- When deploying network policies, thoroughly test them.
- Keep your network policies up-to-date.
- Network policy management tools ease policy generation and management.
Q.55 How does Kubernetes handle log management, and what are some best practices for managing logs in a Kubernetes environment?
Kubernetes manages logs in several ways. Kubernetes automatically keeps container logs on the host filesystem, which may be retrieved via kubectl. Kubernetes supports Fluentd, Elasticsearch, and Stackdriver logging plugins to centralise log management and offer features like log aggregation, searching, and visualisation.
Use these best practises to manage logs in Kubernetes:
- Employ a centralised logging solution: Instead of depending on individual container logs, consider a solution that can collect and store logs from all containers in the cluster. Logs and issues are easier to manage.
- Establish log retention policies: To avoid taking up disc space, implement log retention policies that determine how long logs should be kept before being erased.
- Usage log rotation: Log rotation involves creating new log files and transferring old ones to a different location. This prevents log files from growing too huge and affecting system performance.
- Structured logging makes log messages easier to read and analyse. For difficult issues, this is helpful.
- Monitor logs: To find and fix issues before they become critical, monitor logs routinely.
Q.56 Can you explain how Kubernetes handles container storage, and what are some best practices for managing storage in a Kubernetes environment?
Kubernetes’ storage plugins and volumes handle storage. These plugins and volumes can store containerized apps in Kubernetes pods.
Kubernetes’ emptyDir, hostPath, and persistentVolumeClaim plugins let administrators provide pods storage. Kubernetes integrates with GlusterFS, Ceph, and NFS.
Kubernetes storage best practises:
- Dynamic volume provisioning: Instead of manually deploying storage for each pod, dynamic volume provisioning automatically does it. Kubernetes’ StorageClass API provides dynamic volume provisioning.
- Persistent Volume Claims (PVCs): PVCs seek storage from a storage class. Developers can declare application storage requirements without knowing the storage infrastructure.
- StatefulSets handle stateful applications in Kubernetes by creating and scaling pods in a predefined order. Persistent storage applications need this.
- Storage Quotas: Kubernetes namespaces can be limited by storage quotas. This prevents one app from hogging full storage.
- Portworx and Rook are container-native storage solutions built for Kubernetes environments. Data management, replication, and disaster recovery assist simplify Kubernetes storage management.
Q.57 What is Kubernetes StatefulSet, and how can it be used to manage stateful applications in a Kubernetes environment?
Kubernetes StatefulSet manages stateful applications. Stateful apps need persistent storage and unique network identities. StatefulSet manages network identities and persistent storage for stateful Kubernetes applications.
Databases, key-value stores, and message brokers employ StatefulSet for solid network identities and permanent storage. It lets you handle stateful applications as a group with distinct names and identities rather than generic labels.
StatefulSet features:
- Ordered pod creation and deletion: StatefulSet creates and deletes pods in a predictable and ordered manner.
- StatefulSet pods have consistent hostnames and network IDs that survive rescheduling and scalability. Clients can connect to the same pod even if it is rescheduled to a new node.
- StatefulSet lets you provide persistent storage for each pod, preserving data even if the pod is rescheduled or removed.
Storage management best practises in Kubernetes include:
- Stateful applications that need persistent storage use StatefulSet. Employ persistent volumes (PV) and persistent volume claims (PVC) to store StatefulSet pods.
- Dynamically provision storage using storage classes.
- To schedule pods on nodes with enough storage, use node affinity and anti-affinity.
Q.58 How does Kubernetes handle autoscaling, and what are some best practices for configuring Kubernetes autoscaling?
Horizontal pod autoscaling (HPA) in Kubernetes dynamically scales deployment or replica set replicas based on pod CPU use. HPA can maintain a minimum and maximum number of copies and a target CPU utilisation percentage. Kubernetes automatically scales up or down replicas based on CPU utilisation.
In addition to HPA, Kubernetes enables cluster-level autoscaling through cluster autoscaler, which automatically scales infrastructure resources like nodes to meet pod requests. Cluster autoscaler can be setup with minimum and maximum nodes and scaling rules based on cluster resource use.
Kubernetes autoscaling requires careful setting of goal metrics and thresholds depending on application traffic patterns. To maximise performance and resource consumption, check resource utilisation and modify autoscaling as appropriate. Additionally, the application must be designed to grow horizontally and that data and state are appropriately handled and replicated among scaling replicas.
Q.59 What is Kubernetes Operator, and how can it be used to manage complex applications in a Kubernetes environment?
Kubernetes Operator automates complicated applications and services by expanding the API. Developers can construct custom controllers to automate application and service deployment, configuration, and management.
Developers who know the programme or service they manage produce operators. They build custom resource definitions (CRDs) that describe the application or service and its desired state, then use a controller to monitor the application and make changes to keep it in the desired state.
Kubernetes Operator simplifies deployment and management of complex apps and services by automating and managing them within Kubernetes. Developers can define bespoke behaviour for controlling their apps or services using Kubernetes Operator and trust it to keep the correct state.
Kubernetes Operator best practices:
- Reusable Operator design.
- Creating tests and leveraging CI/CD to make the Operator dependable and updateable.
- Building an Operator Hub or comparable platform for developer collaboration and sharing Operators.
- Clear documentation and tutorials for Operator use.
- Constantly updating the Operator to handle new Kubernetes and dependency versions.
Q.60 Can you explain how Kubernetes handles security, and what are some best practices for securing Kubernetes clusters?
Kubernetes includes several security features and recommended practises. Kubernetes security includes:
Authentication and Authorization: Kubernetes controls cluster resource access through RBAC. LDAP or Active Directory can authenticate users and permit them to perform cluster tasks based on their role and permissions.
Network Security: Network policies in Kubernetes allow pods to communicate with one other and external networks. Network policies can restrict access by IP address, port, or other factors.
Container Security: Container runtime security in Kubernetes protects containers against malicious attacks. Kubernetes can analyse container images for vulnerabilities and dangerous code.
Secrets Management: Kubernetes’ built-in secrets management system secures API keys, passwords, and certificates. Kubernetes APIs let authorised users and apps access encrypted secrets at rest and in transit.
Auditing and Logging: Kubernetes has auditing and logging features to track user activity and detect suspicious behaviour. Third-party programmes can examine Kubernetes logs to reveal cluster activities.
Kubernetes cluster security best practises:
- Update Kubernetes with security fixes and updates.
- Employ RBAC-based authentication and authorization.
- Network policies prohibit pod-external network access.
- SELinux or AppArmor can protect containers against harmful assaults.
- Secrets management protects sensitive data.
- Check Kubernetes logs for suspicious behaviour.
- Utilize third-party Kubernetes security tools and services.
- Do security assessments and penetration testing to find and fix cluster vulnerabilities.
Q.61 What is Kubernetes admission control, and how can it be used to enforce policies in a Kubernetes environment?
Kubernetes admission control plugins can enforce policies on cluster-created or modified objects. Admission control intercepts Kubernetes API requests before the API server processes them.
Kubernetes admission controllers validate and alter items, enforce security standards, and automate operations. NodeRestriction, PodSecurityPolicy, and ResourceQuota are built-in admission controllers, and bespoke ones can apply customised policies.
PodSecurityPolicy admission controller can prohibit the use of privileged containers in Kubernetes or enforce specified security contexts for pod-running containers. ResourceQuota admittance controller can limit namespace resource consumption to prevent a single application from using all available resources.
Admission control policies guarantee that Kubernetes resources are produced and maintained according to the organization’s standards and best practises, preventing security vulnerabilities and other difficulties. Enabling only necessary admission controllers, testing rules in a non-production environment, and monitoring and troubleshooting policy enforcement with audit logs are admission control best practises.
Q.62 How does Kubernetes handle cluster upgrades, and what are some best practices for upgrading Kubernetes clusters?
Kubernetes improvements include control plane and worker node upgrades. To minimise application downtime, Kubernetes cluster upgrades are difficult.
Kubernetes offers big and minor improvements. Significant Kubernetes API version upgrades need more cluster changes than minor component upgrades.
Best practises for Kubernetes cluster upgrades include:
- Upgrade: Check Kubernetes component compatibility, understand new version changes, and plan backup and restore methods.
- First, upgrade the API server, etcd, scheduler, and controller manager. Rolling component upgrades reduce downtime.
- Upgrade worker nodes one by one to keep apps running. Rolling upgrades reduce disruption.
- Upgrade test: Check all applications and services on the upgraded cluster.
- To avoid performance difficulties and failures, closely monitor the upgraded cluster.
- Rollback plan: If the update fails, have a plan with backups.
Q.63 Can you explain how Kubernetes handles monitoring and metrics, and what are some best practices for monitoring Kubernetes clusters?
Kubernetes has many built-in and third-party tools for monitoring and gathering metrics.
The Kubernetes API server exposes a comprehensive collection of metrics that Prometheus may scrape. The Kubernetes Metrics Server collects resource consumption measurements from the API server for horizontal pod autoscaling and other uses.
The Kubernetes API server receives node-level information from the kubelet, which runs on each cluster node and manages containers. Monitoring tools can gather and analyse kubelet container runtime and resource consumption metrics.
Grafana, Elasticsearch, and Fluentd can be integrated with Kubernetes in addition to these built-in components. These tools collect, view, and analyse Kubernetes cluster metrics and logs.
Kubernetes cluster monitoring best practises:
- Employ a Kubernetes-specific monitoring tool with built-in metrics and log analysis.
- Configure warnings for node failures, pod evictions, and resource use increases.
- Monitor component interactions like pod-service network traffic.
- Labels and annotations organise measurements and logs and offer metadata for investigation and troubleshooting.
- Review monitoring data to spot trends and fix concerns before they become critical.
- Distributed tracing can reveal request performance and behaviour in the Kubernetes cluster.
Q.64 What is Kubernetes federation, and how can it be used to manage multiple Kubernetes clusters across different regions or clouds?
Kubernetes federation allows central resource and policy management across numerous clusters from a single control plane. This helps manage clusters across regions or clouds.
A federated API server and controller manager manage the lifecycle and control plane of federated resources in Kubernetes federation.
Kubernetes federation lets administrators deploy and manage applications and settings like quotas and security across numerous clusters from a single control plane. This simplifies management of several clusters.
Kubernetes federation best practises include planning the cluster layout, considering network connection, and using namespaces to logically divide resources across clusters. It’s also crucial to frequently test the federation configuration and have a solid disaster recovery plan.
Q.65 How does Kubernetes handle container isolation, and what are some best practices for ensuring container isolation in a Kubernetes environment?
Kubernetes isolates containers on the same node or across nodes. Docker uses namespaces, cgroups, and SELinux to isolate containers.
Network, pod, and runtime security settings in Kubernetes can improve container isolation. Network policies restrict network traffic between pods or namespaces, while pod security policies enforce pod security. AppArmor or Seccomp can limit a container’s system calls, further isolating it.
Kubernetes container isolation recommended practises:
- Use a container runtime with strong isolation.
- Network policies restrict pod or namespace traffic.
- Pod security regulations ensure pod security.
- Runtime security limits container system calls.
- Restrict container access to the minimum needed for their functions. Before deploying to Kubernetes, scan secure container images for vulnerabilities.
- Update container images and the operating system regularly to apply security fixes.
Q.66 Can you explain how Kubernetes handles container networking plugins, and what are some best practices for configuring Kubernetes networking plugins?
Kubernetes supports container networking with pluggable networking plugins. These plugins create a virtual network that connects all Kubernetes cluster containers.
Popular Kubernetes networking plugins include:
- Flannel: An easy-to-use networking plugin connects containers using virtual networks. Little to medium-sized clusters prefer it.
- Calico: This powerful networking plugin offers policy-based network security and complicated network topologies.
- Weave Net: Another popular networking plugin for Kubernetes clusters provides easy and scalable network infrastructure.
Kubernetes networking plugin best practices:
- Choose a Kubernetes-compatible networking plugin.
- Choose a networking plugin that meets your needs.
- Use a non-overlapping network CIDR in your networking plugin.
- Network policies manage pod and namespace traffic.
- Monitor network traffic for irregularities and security concerns.
Q.67 What is Kubernetes affinity and anti-affinity, and how can it be used to optimize resource utilization in a Kubernetes environment?
Kubernetes affinity and anti-affinity allow pod scheduling and placement depending on cluster node co-location or spread. Affinity rules prefer scheduling pods on nodes with specified labels, annotations, or labels. Anti-affinity rules prohibit scheduling pods on the same node or with specific other pods.
Affinity and anti-affinity rules help enhance Kubernetes resource use by distributing pods uniformly among nodes and placing them on nodes with sufficient resources. An affinity rule may schedule a database pod on a node with SSD storage, while an anti-affinity rule could prevent several pod instances from running on the same node to reduce resource congestion.
Kubernetes affinity/anti-affinity best practices:
- Label and annotation node and pod properties for affinity and anti-affinity rules.
- Topology keys can provide node or zone affinity and anti-affinity rules.
- Soft affinity and anti-affinity rules enable pod scheduling flexibility.
- Employ pod affinity and anti-affinity rules to colocate or split pods based on their dependencies.
- To ensure pod scheduling and placement, test affinity and anti-affinity rules before deploying them.
Q.68 How does Kubernetes handle service mesh integration, and what are some best practices for integrating Kubernetes with service meshes like Istio or Linkerd?
Kubernetes deploys and manages containerized applications but doesn’t include service discovery, traffic routing, or load balancing. Service meshes help. Service meshes manage traffic, secure interactions, and enforce policies across applications and networks.
Kubernetes may integrate with service meshes like Istio or Linkerd to add networking and security to containerized applications. Service meshes intercept network communication between containers using sidecar proxies for traffic management, observability, and security.
To integrate Kubernetes with a service mesh, you typically install the control plane onto the cluster and configure your services to use the mesh’s sidecar proxies for traffic management. Kubernetes service mesh integration recommended practices:
- Start with a modest set of services: When integrating with a service mesh, start with a small set and gradually add more services. This lets you spot and fix issues early.
- Service meshes usually have an ingress gateway for routing external traffic. The ingress gateway simplifies networking and adds mutual TLS authentication.
- Service meshes can add latency and overhead to your application’s network traffic, therefore it’s crucial to monitor your application’s performance and identify any service mesh-related issues.
- Service meshes have many functions for controlling traffic, protecting communications, and enforcing policies. However, not all functions are necessary or acceptable for your application, so utilise them wisely and just enable the ones you need.
Q.69 What is Kubernetes vertical pod autoscaling, and how can it be used to optimize resource utilization in a Kubernetes environment?
Kubernetes Vertical Pod Autoscaling (VPA) automatically adjusts a container’s CPU and memory resources to maximise resource consumption and application performance.
VPA analyses CPU and memory consumption data from Kubernetes containers to determine if they are over- or under-provisioned. Based on this data, VPA can alter resource demands and limitations for individual containers or deployments to ensure efficient resource usage.
VPA operates in “recommended” or “enforced” modes. VPA recommends resource adjustments in “recommended” mode, but the cluster operator decides whether to accept them. In “enforced” mode, VPA adjusts container and deployment resource requests and restrictions without operator interaction.
Kubernetes VPA best practices:
- Start with suggested mode: To study VPA recommendations before applying them, start with recommended mode.
- Custom measurements: VPA can change resources using CPU and memory metrics or custom metrics. Custom metrics can improve resource utilisation data for applications with specific resource needs.
- Monitor and tune: Periodically check VPA suggestions and alter VPA settings to optimise container resources.
- Test thoroughly: Before enabling VPA in production, test it in a development or staging environment to confirm it is fully setup and performing as expected.
Q.70 Can you explain how Kubernetes handles high availability, and what are some best practices for ensuring high availability in a Kubernetes environment?
Kubernetes has various capabilities and best practises to make applications and services highly available.
- Cluster architecture: Kubernetes lets you deploy numerous master and worker nodes across availability zones or regions to construct highly available clusters. This keeps the cluster running if a node or zone fails.
- Replication: Kubernetes uses replication controllers and replica sets to keep a set number of pod replicas operational. Kubernetes replaces failed pods with new replicas.
- Load balancing: Kubernetes provides numerous load balancing algorithms to evenly distribute traffic among pods or nodes. Preventing overburden and increasing availability.
- Kubernetes allows rolling updates and rollbacks without downtime. To ensure application availability, outdated pods are gradually replaced with fresh ones.
- Liveness and readiness probes: Kubernetes examines pod and service health. These probes may automatically remove or replace unhealthy pods, ensuring only healthy pods serve traffic.
- Persistent storage: Kubernetes offers stateful sets and persistent volumes to keep data available after pod failure or termination.
- Disaster recovery: Kubernetes can backup and restore from node or data centre failures.
Q.71 How does Kubernetes handle container image management, and what are some best practices for managing container images in a Kubernetes environment?
Kubernetes supports many container image management methods. Docker Hub, Google Container Registry, and Amazon Elastic Container Registry are popular options.
Kubernetes manages container images in a registry. Kubernetes takes container images from the registry when creating a pod. Kubernetes can use a specific container image registry for a collection of pods or namespaces.
Best practices for managing container images in Kubernetes:
- Container image tags describe the container image version. This simplifies container image management and guarantees that fresh pods utilise the proper image version.
- Private container image registries improve security and control. Container images should be managed in a private registry.
- Scan container images before deploying them in Kubernetes.
- Image pull policies tell Kubernetes when to pull container images from a registry. Use a pull policy to always utilise the latest image.
- Image caching improves efficiency and reduces container image registry load. Caching container images on Kubernetes nodes speeds pod deployment.
Q.72 What is Kubernetes node affinity, and how can it be used to optimize pod placement in a Kubernetes environment?
Kubernetes node affinity lets you set node label-based pod scheduling rules. Node affinity controls pod scheduling based on node labels.
Node affinity lets you always schedule pods on certain cluster nodes. Scheduling pods near data or on nodes with specialised hardware resources can improve performance.
The nodeSelector field in a pod’s setup lets you provide label selectors for the pod’s nodes. You may also specify preferred or needed scheduling nodes using the preferredDuringSchedulingIgnoredDuringExecution parameter.
Q.73 Can you explain how Kubernetes handles application upgrades, and what are some best practices for upgrading Kubernetes applications?
Kubernetes offers several ways to upgrade apps on a cluster. Rolling upgrades eventually replace old application instances. Rolling updates can release a new application version, scale replicas, or change deployment configuration.
Kubernetes replaces pods one by one during a rolling update to maintain a specific number of pods and keep the application running. Kubernetes lets you regulate pod replacement and define a readiness probe to check if a pod is ready to receive traffic before adding it to the service.
Canary deployments in Kubernetes include distributing a new version of the application to a small subset of pods and gradually raising the percentage of pods running it while monitoring the application’s behaviour. This lets you test the new version before deploying it to the cluster.
To ensure a successful update, use a version control system to manage application code, keep configuration separate from code, and test the upgrade process in a staging environment before releasing to production. To ensure application consistency across the cluster, employ container images with version tags.
Q.74 What is Kubernetes network plugins, and how can they be used to extend Kubernetes networking functionality?
Kubernetes network plugins govern pod communication and external communication. The Kubernetes CNI plugin generates a flat network that connects all pods on all nodes by default. Kubernetes offers a range of network plugins to satisfy the needs of more sophisticated installations.
Popular Kubernetes network plugins:
- Calico: Enforces network governance and supports layer 2 and 3 topologies.
- Flannel: Creates a cross-datacenter or cloud provider overlay network.
- Weave Net: Automatic IP address management and different network topologies.
- Cilium: eBPF-based network security and policy enforcement.
Q.75 How does Kubernetes handle container resource allocation, and what are some best practices for optimizing resource allocation in a Kubernetes environment?
Resource requests and limits in Kubernetes allocate container resources. Resource requests and limitations are the minimum and maximum resources a container can utilise.
Kubernetes schedules containers onto nodes based on their resource needs and guarantees that all containers on a node do not exceed its capacity. Kubernetes also imposes container resource limitations to prevent overuse.
Kubernetes resource allocation recommended practices:
- Correctly indicate container resource requests and restrictions to help Kubernetes schedule containers and avoid resource contention on nodes.
- Monitor resource utilisation: Monitoring container and node resource usage can help determine when more resources are needed or when containers are using too much.
- Horizontal pod autoscaling automatically scales deployment replicas based on resource utilisation, ensuring that applications have enough resources to meet rising traffic.
- Employ Kubernetes resource quotas to prevent resource contention and ensure equitable resource allocation.
- Use node selectors and affinity to schedule pods on nodes with the right resources and capabilities.
- Minimize container resource utilisation: Minimizing resource usage or reducing container size can help maximise resource efficiency.
Q.76 Can you explain how Kubernetes handles horizontal pod autoscaling, and what are some best practices for configuring Kubernetes autoscaling?
Horizontal Pod Autoscaling (HPA) in Kubernetes scales pods based on CPU and memory use. To guarantee the application can handle the increased load, the HPA controller automatically adjusts the number of replicas when a pod’s resource use reaches a threshold. When resource use drops, the HPA controller cuts copies to optimise resource use.
Best practices for configuring Kubernetes autoscaling:
- Choosing suitable scaling goals is crucial while configuring HPA. The application’s load and performance should be reflected in the metrics. Scaling metrics include CPU, memory, and custom.
- As resource use reaches or falls below a threshold, HPA ramps up or down. To avoid overprovisioning or underprovisioning resources, set these criteria properly. Set the threshold to the pod’s peak load average utilisation.
- Employ cluster autoscaling: Based on resource use, cluster autoscaling automatically modifies the number of nodes in the cluster, ensuring HPA has adequate resources to scale up pods. Cluster autoscaling and HPA can optimise resource utilisation and decrease expenses.
- Utilize an HPA with an HPA to optimise replicas. For instance, you may utilise HPAs to scale pods up or down based on CPU or memory use.
- Test and iterate: The HPA configuration must be tested and iterated to optimise it for the application. When the application changes, regular testing and iteration helps keep the HPA configuration effective.
Q.77 What is Kubernetes pod disruption budget, and how can it be used to ensure high availability in a Kubernetes environment?
In Kubernetes, a pod disruption budget limits the number of pods that can be down at once during a disruption event like node maintenance or upgrade. While operating stateful applications that need data consistency and availability, it controls how many pods can be unavailable at once.
A Kubernetes resource named PodDisruptionBudget (PDB) provides the minimum number of replicas for a pod set. Kubernetes aims to keep the number of unavailable replicas below the budget after a disruption.
Kubernetes will disallow pod terminations if a PDB allows only one replica to be down at a time. This guarantees the application has enough clones for its intended availability.
Q.78 How does Kubernetes handle workload migration, and what are some best practices for migrating workloads in a Kubernetes environment?
Kubernetes has numerous ways to migrate workloads between nodes or clusters. Kubernetes API migration is a frequent method.
The Kubernetes API can adjust the pod specification, including the node selection and affinity rules, to transfer a workload. Update these specs to reschedule the pod to a new node in the same or an other cluster.
Kubectl or Kubernetes Dashboard can also be used to migrate. This method entails building a new deployment or statefulset with the new node or cluster and scaling down the current one. Scale up the new deployment or statefulset to handle the burden.
Q.79 Can you explain how Kubernetes handles container orchestration and scheduling, and what are some best practices for optimizing container orchestration and scheduling in a Kubernetes environment?
Kubernetes orchestrates and schedules containers using components and algorithms. The Kubernetes control plane includes the API server, etcd, kube-scheduler, kube-controller-manager, and cloud-controller-manager. These components schedule and orchestrate containerized applications.
Kubernetes specifies application states declaratively. YAML files or the Kubernetes API define the intended state, and Kubernetes handles the specifics. Based on resource requirements, availability, and other constraints, Kubernetes schedules containers onto cluster nodes.
Kubernetes container orchestration and scheduling best practises include:
- Kubernetes allocates container resources using resource requests and restrictions. Configuring these variables correctly prevents resource contention and optimises performance.
- Kubernetes provides horizontal pod autoscaling based on resource use indicators. Horizontal pod autoscaling can maintain the workload-based replica count.
- Employ node affinity and anti-affinity to regulate pod placement in Kubernetes. This ensures pods are scheduled on nodes with GPU support or SSD storage.
- Employ pod affinity and anti-affinity to regulate pod placement in Kubernetes. This ensures pods are scheduled on nodes with specific pods running or not.
- Utilize pod priority and preemption: Kubernetes lets users set pod priority and preemption rules to prioritise high-priority pods and preempt lower-priority pods.
Q.80 Can you explain the difference between Kubernetes pods and containers, and how they are related?
Kubernetes pods and containers are similar yet serve different purposes.
Code, libraries, and dependencies are included in a lightweight, standalone executable software container. Containers are portable and segregated from their host system and other containers.
A Kubernetes pod is the smallest deployable item that represents a single process in a cluster. One or more containers can share a pod’s network namespace and shared volumes. Pod containers function together.
Hence, a pod hosts one or more tightly connected containers that share resources and dependencies and are scheduled on the same worker node. The containers in a pod are co-located and co-scheduled, meaning they are always deployed and managed together and share the same network namespace, IPC namespace, and other resources.
Q.81 How does Kubernetes handle container scaling, and what are some best practices for configuring container scaling in a Kubernetes environment?
Kubernetes offers horizontal pod autoscaling (HPA) and vertical pod autoscaling to scale containerized workloads (VPA).
Horizontal pod autoscaling scales pod replicas by CPU or memory utilisation. Kubernetes automatically adds replicas to meet increased workload when metrics surpass thresholds.
Vertical pod autoscaling optimises resource requests and restrictions based on usage. This lets the container consume more or release unused resources as needed.
In a Kubernetes context, resource demands and limitations for each container in a pod help Kubernetes predict the application’s resource needs. Monitor application resource utilisation and modify HPA and VPA thresholds.
Q.82 What is Kubernetes deployment, and how can it be used to manage container deployments in a Kubernetes environment?
Deployments in Kubernetes create and scale identical pods. It declaratively manages Kubernetes container deployments to keep the required number of replicas operational.
YAML or JSON files describe a deployment’s container image, replica count, and other configuration settings. The deployment controller then creates or deletes pods to match the application state.
Rolling updates let you upgrade a container image or application configuration without downtime using the deployment controller. The application stays available by progressively replacing outdated pods with new ones.
Q.83 Can you explain how Kubernetes handles container health checks, and what are some best practices for configuring container health checks in a Kubernetes environment?
Container health checks are required in Kubernetes to monitor pod-level container health. Health checks tell Kubernetes if a container is working and should receive traffic.
Kubernetes has liveness and readiness container health checks. A liveness probe checks if a container is running, while a readiness probe checks for traffic readiness.
YAML or JSON pod specifications can define probes for Kubernetes container health checks. The pod specification lets you specify the probe type, port, path to the probe endpoint, and interval.
Kubernetes container health check best practices include:
- Liveness and readiness probes verify containers are running properly and ready for traffic.
- Set probe thresholds like the number of failures before a container is unhealthy.
- Run probes periodically to discover container issues before they become critical.
- Check the container image’s probe endpoint implementation and status codes.
- Monitor container health with metrics and logging to prevent application performance concerns.
Q.84 What is Kubernetes namespace, and how can it be used to manage Kubernetes resources?
Namespaces in Kubernetes allow users to divide resources into logical groups. It helps manage resources and access control in large, multi-team organisations by creating a name scope.
Namespaces divide cluster items like services, deployments, and pods. This reduces resource waste and naming conflicts.
Namespace isolates applications, resources, and services. RBAC manages permissions for distinct individuals or teams. For instance, a namespace for a team or application can restrict access to its resources.
Kubernetes namespace best practices:
- Namespace resources by application, team, or environment. RBAC restricts namespace resources.
- Too many namespaces can complicate management.
- Name namespaces descriptively to make their purpose clear.
- Review and delete unneeded namespaces to free up resources and eliminate clutter.
Q.85 How does Kubernetes handle container image registry, and what are some best practices for managing container images in a Kubernetes environment?
Kubernetes’ “container registry” manages container images. It stores and distributes container images in a Kubernetes cluster, making containerized applications easy to manage and deploy.
Container image management best practises in Kubernetes include:
- Use a private container registry: A private registry restricts access to container images to authorised users, preventing data breaches.
- Scan images for vulnerabilities: Before delivering container images to your Kubernetes cluster, make sure they don’t have any security flaws that might be exploited.
- Employ image tagging: Labeling container pictures with version numbers or other identifiers makes it easier to manage and track changes over time.
- Pull images: Kubernetes uses image pull policies to update container images. You can configure Kubernetes to check for updates at regular intervals or only when a new deployment is required. By default, it downloads images from the registry as needed.
- Access-controlled image registries can help you manage container image access in your environment.
Q.86 What is Kubernetes config map, and how can it be used to manage application configuration in a Kubernetes environment?
Applications in Kubernetes may need database URLs, API keys, and other parameters. Manually managing setups is time-consuming and error-prone. ConfigMaps solve this in Kubernetes.
A Kubernetes cluster application can consume configuration data from a ConfigMap. ConfigMaps hold application configurations, command-line arguments, environment variables, and more.
YAML or kubectl build ConfigMaps. They can be mounted as pod volumes or container environment variables after creation. Applications can access their configurations without hard-coding them into images or containers.
ConfigMaps are advantageous:
- Centrally manage and version configuration data.
- Decoupling configurations from application code makes applications more portable.
- Configuration updates don’t require redeploying.
- Same-configuration applications scale effortlessly.
ConfigMap best practices:
- ConfigMaps by application or service for simpler management.
- Descriptive keys for configuration data improve readability.
- instead of ConfigMaps.
- Keeping ConfigMaps minimal reduces data loss in a failure.
- Creating and managing ConfigMaps with controllers or operators.
Q.87 Can you explain how Kubernetes handles container networking, and what are some best practices for configuring Kubernetes networking in a multi-node environment?
Kubernetes gives each pod an IP address in a flat networking paradigm. Kubernetes networking employs the Container Network Interface (CNI) to offer pluggable networking solutions.
Kubernetes employs Services for load balancing and service discovery in multi-node environments. Each service has a stable IP address and DNS name for cluster-wide access.
Best practices for multi-node Kubernetes networking include:
- Use a CNI plugin optimised for your environment.
- Isolate Kubernetes traffic from host traffic via a dedicated network interface.
- Network policies allow pods to communicate with one other and external resources.
- Utilize Istio or Linkerd for advanced traffic management and observability.
- Using the host network namespace for pods poses security vulnerabilities and makes network traffic management difficult.
- Improve network performance and security with a network plugin that supports segmentation.
Q.88 How does Kubernetes handle container storage, and what are some best practices for managing storage in a Kubernetes environment?
In Kubernetes, containers often need to store persistent data. For this, Kubernetes offers:
- EmptyDir: A simple in-memory storage volume that is generated when a Pod is scheduled on a node and destroyed when the Pod is deleted.
- HostPath: A volume that mounts a file or directory from the host node’s disc into the Pod. Accessing data outside the container is possible with this.
- Administrator-provisioned persistent volumes (PV): This can be an NFS mount, block device, or other storage resource. A StorageClass can provision persistent volumes dynamically.
- Persistent Volume Claims (PVC): Pods request storage with PVCs. When a Pod needs storage, it requests a PVC and binds it to a PV.
Storage best practises in Kubernetes include:
- When a PVC is formed, use StorageClasses to dynamically provision storage. Kubernetes storage management is easier using StorageClasses.
- Utilize PVCs: As PVCs isolate storage from Pods, they can be moved between cluster nodes more simply.
- Utilize StatefulSets: Stateful applications need persistent storage. StatefulSets construct Pods with unique names and network IDs in a predictable order.
- Node affinity rules can be used to schedule Pods on storage-capable nodes.
- Choose the right storage type: Various storage types have varied performance characteristics, so choose the right one for your application. Block storage is good for databases, while object storage is good for huge files.
- To avoid running out of storage, monitor Kubernetes storage consumption. Storage utilisation can be monitored using Kubernetes’ built-in metrics and third-party tools.
Q.89 What is Kubelet?
Kubelet is the principal node agent on each Kubernetes node. It maintains the node’s containers. The Kubelet interacts with container runtimes like Docker to launch, stop, and manage containers and receives scheduling instructions from the Kubernetes control plane. Kubelet also monitors container health and transmits it to the control plane, which can fix or replace unhealthy containers. Kubelet controls containers and maintains the health of the Kubernetes node.
Q.90 What is Kubectl?
Kubectl is a command-line utility for Kubernetes. It deploys, inspects, and manages Kubernetes applications. Kubectl creates, updates, and deletes Kubernetes pods, deployments, services, and more. Kubectl lets users monitor logs, check cluster status, and perform commands in containers on pods. Developers, administrators, and DevOps engineers need Kubectl to manage Kubernetes clusters.
Q.91 What do you understand by Cloud controller manager?
Kubernetes’ CCM interfaces with cloud provider APIs. Kubernetes uses cloud provider APIs to generate and manage load balancers, virtual machines, and storage volumes. CCM handles cloud infrastructure using the cloud provider’s API server as a Kubernetes controller. The CCM makes Kubernetes cloud-agnostic, allowing it to run on numerous cloud providers without modification.
Q.92 What is Minikube?
Minikube runs Kubernetes locally for development, testing, and experimentation. It creates a single-node Kubernetes cluster within a VM on your local PC and allows you to deploy and manage apps without a production-grade cluster. Developers and Kubernetes aficionados use Minikube to test new features, apps, and concepts in a sandbox.
Q.93 What is ‘Heapster’ in Kubernetes?
Heapster is a Kubernetes add-on component that collects and aggregates metrics from the API server, kubelet, and container runtimes. It tracks pod, container, and node resource utilisation in Kubernetes clusters. Heapster uses the Kubernetes API to collect these metrics and store them in a time-series database that can be viewed with Grafana or InfluxDB. The Kubernetes Metrics Server, which collects and exposes resource consumption metrics in Kubernetes clusters, has replaced Heapster since version 1.11.
Q.94 How can you get a static IP for a Kubernetes load balancer?
Cloud load balancer services can supply Kubernetes load balancers with static IPs. For static IPs for load balancers, visit your cloud provider’s documentation.
With Google Cloud Platform, you can use the gcloud command line tool to reserve a static IP address and then specify it when launching a LoadBalancer Kubernetes service.
gcloud compute addresses create my-static-ip --region us-central1Then, when creating a Kubernetes service with type LoadBalancer, you can specify the reserved IP address in the service definition:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: LoadBalancer
loadBalancerIP: <reserved-static-ip>
ports:
- port: 80
targetPort: 8080
selector:
app: my-appWhen the service is created, the cloud provider’s load balancer service will assign the reserved IP address to the load balancer that is created for the service.
To get a static IP for a Kubernetes load balancer in Azure, you can reserve a static public IP address in Azure and then assign it to your Kubernetes service as a load balancer. Here are the steps to follow:
- Reserve a static public IP address in Azure. This can be done through the Azure portal or using the Azure command-line interface (CLI). For example, you can use the following command to create a new static IP address:
az network public-ip create --resource-group <resource-group> --name <ip-name> --allocation-method StaticCreate your Kubernetes service with a load balancer. You can use a Kubernetes manifest file or the kubectl command-line interface to create your service. For example, you can create a service with a load balancer using the following manifest file:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: LoadBalancer
loadBalancerIP: <static-ip-address>
selector:
app: my-app
ports:
- name: http
port: 80
targetPort: 8080Note that you need to specify the reserved static IP address in the loadBalancerIP field.
Once the service is created, Kubernetes will create a new load balancer in Azure and assign the static IP address to it.
Q.95 What are federated clusters?
Federated clusters allow Kubernetes to manage several clusters as a single entity. Federated clusters allow a single entity to manage several Kubernetes clusters in different geographies, cloud providers, or on-premise data centres. This simplifies complex environments by centralising cluster management, monitoring, and control. The Federated API server manages and synchronises resources and configurations across federated clusters.
Q.96 What is the difference between a replica set and a replication controller?
Pod scalability in Kubernetes is handled via a ReplicaSet and a ReplicationController.
ReplicationControllers were the first Kubernetes controllers to ensure a pod’s replicas were running at all times. If the pod fails or terminates, the ReplicationController produces a new one. Stateful sets and Pods with unique IDs are unsupported by the ReplicationController.
Nevertheless, a ReplicaSet is an improved ReplicationController that can handle the uniqueness of stateful sets or Pods. ReplicaSets ensure that a set number of pod replicas with distinct identities are running at any given moment. It can also build new Pods and replace unsuccessful ones.
Q.97 What is NodePort?
Kubernetes’ NodePort service type exposes a group of pods to the outside network on each cluster node’s static port. Kubernetes automatically opens a port on all nodes in the cluster when a NodePort service is launched, and traffic to that port is redirected to the pods the service targets. External clients can access a Kubernetes cluster service using a static IP address and port number.
When there is no LoadBalancer or Ingress controller or when a service needs a static IP address, NodePort can expose it outside. It can be used in production with a load balancer or external DNS to ensure high availability and reliability.
Q.98 What are the different services within Kubernetes?
In Kubernetes, there are different types of services that can be used to expose pods and provide networking for containerized applications. These include:
- ClusterIP: This service provides a stable IP address that is only accessible within the cluster. It can be used to expose pods to other pods or services within the same Kubernetes cluster.
- NodePort: This service exposes the same port on each selected node in the cluster. It is useful for exposing a service externally to the cluster, typically for development or testing purposes.
- LoadBalancer: This service creates an external load balancer in cloud environments, such as AWS or GCP, to distribute traffic to pods within the cluster.
- ExternalName: This service maps a service to a DNS name, allowing applications to refer to the service by name instead of by IP address.
- Headless: This service is used for stateful sets, where each pod needs a unique DNS name for direct communication. The headless service allows for the discovery of these individual pod DNS names.
Q.99 Explain Kubernetes Architecture ?
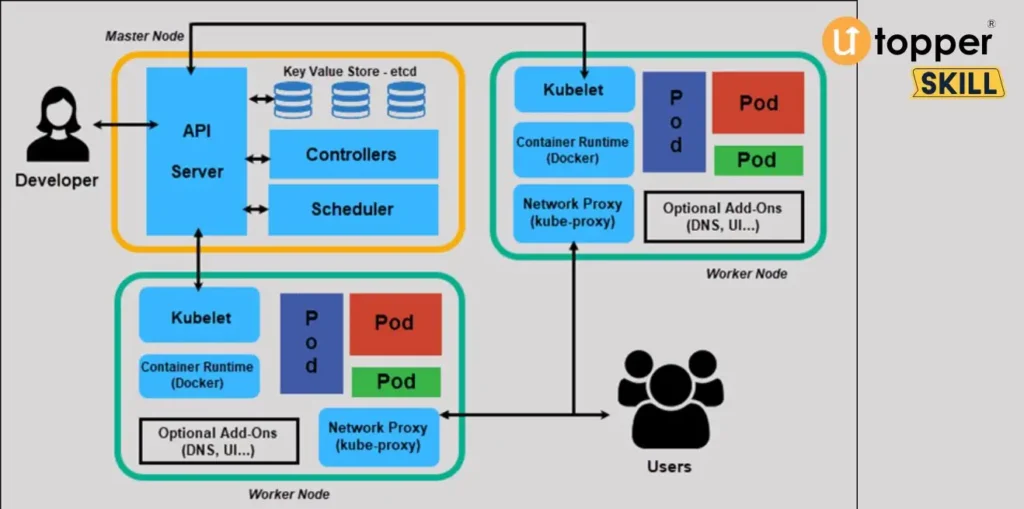
Kubernetes manages distributed containerized applications and resources using a master-slave model. The architecture includes Master components, Worker nodes, and etcd datastore.
Master components on the Master node manage cluster status and Worker node activity. API server, etcd, controller manager, and scheduler.
Worker nodes run the cluster’s containerized apps and services. The Master components teach and report these nodes’ states.
The cluster’s configuration and state data are stored in the distributed key-value store etcd. It’s Kubernetes’ sole truth.
Kubernetes also has networking and security features to let apps interact securely and effectively throughout the cluster.
Check the Devops Interview Questions Here :
Official Website of Kubernetes : https://kubernetes.io/